Hallo zusammen,
in unserer Applikation gibt es die Möglichkeit Belege in verschiedenen Sprachen auszugeben. Die Datenbank wurde auf Unicode umgestellt.
die gesamten Langtexte wie Kundentexte, Artikeltexte, Vor- und Nachtexte in den Formularen werden in der Applikation über ein HTML Editor erfasst und entsprechend in der DB mit dem HTML Code gespeichert.
Für die Ausgabe in den Formularen und Auswertungen verwenden wir die List & Label HTML Komponente innerhalb des Designers.
Allerdings haben wir das Problem, dass die Zeichen nicht korrekt ausgegeben werden. Aus dem polnischen ż wird zum Beispiel z.
Übergebe ich in dem HTML Code ż oder ż dann funktioniert die Ausgabe. In HTML kann ich mit entsprechender Meta Angabe einfach UTF-8 oder 16 deklarieren und dann klappt die Ausgabe auch ohne diese Unicode bzw. HTML Kodierung.
Gruß
Thomas Heine
Hi Thomas,
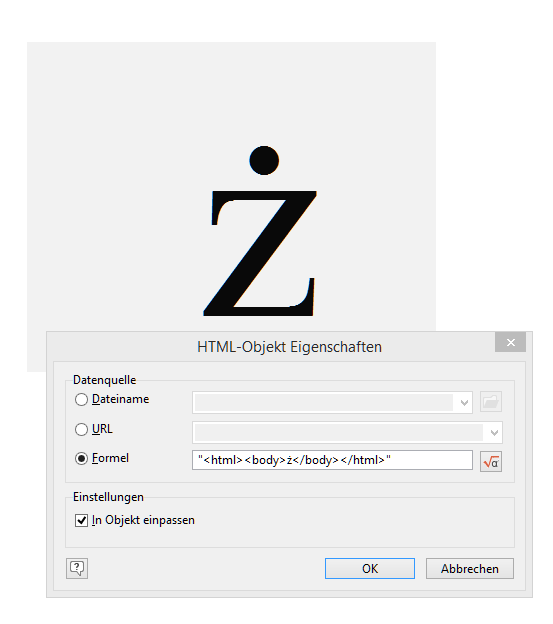
Habe eben mal ganz doof
“ż”
als Inhalt eines HTML-Objekts gewählt (Typ “Formel”) - bei mir geht das, ich bekomme ein z mit Punkt drüber. Versuche mal einen Screenshot anzuhängen.
G.
Hallo,
soweit ich mich da entsinnen kann wurde hier in einem der letzten LL20er Service Packs etwas in Bezug auf “Codierung” etc. angepasst… das habe ich dazu aus dem Release-Readme des aktuellen Service Packs:
cmll20ht.llx 20.002
Getting the internal html source code of the html object itself for rendering in [X]HTML exports, a wrong
codepage could be used for encoding and Umlauts could be missing.
If the html content is given by variable-type LL_HTML, the created temporary file for rendering is now in
UTF-8 format.
Vielleicht hilft diese Info ja auch schon? Und vielleicht ist das auch der Grund wieso es bei Günther funktioniert, weil er das aktuelle LL20er Service Pack verwendet?
Hallo Günther,
welche Version setzt du ein? Ist das wie unten beschrieben die Version 20?
Bei mir klappt das nicht :(.
Ich habe auch genauso wie du einfach den HTML Schnippsel eingetragen und bekomme ein z zu sehen.
Thomas
Hallo zusammen,
nun konnte ich das Problem mit der Version 20 testen, da diese jetzt in unsere ERP Software testweise implementiert wurde.
In der Vorschau sieht jetzt alles wunderbar aus und alle Zeichen werden korrekt dargestellt. Exportiere ich jedoch diese Auswertung in PDF über die interne L&L PDF Routine, sind alle Sonderzeichen weg.
Drucke ich die Auswertung auf einem externen PDF Drucker wie dopdf, pdfcreator… passt alles.
Kann das jemand nachvollziehen. Gibt es da Konfigurationsmöglichkeit um die Texte korrekt auszugeben?
Gruß
Thomas
Hallo,
das sieht hier nun aber ggf. so aus, als ob die Fonts nicht sauber nach PDF kommen… Hierfür gibt es aber die Code-Option “PDF.FontMode” (siehe auch Prog-Ref) - je nach Font und Text kann dieser in PDF anders interpretiert werden.
Interaktiv kann man die Font-Option auch einstellen, in dem man beim Export-Dialog für PDF auf “Optionen” klickt. Ich denke, dass sollte hier schon weiterhelfen?!
Hallo und danke schön für den Beitrag,
Ich habe mir das eben angesehen. Tatsächlich kann die Einbettung der Schriftarten über Optionen vor dem Export eingestellt werden.
Bei mir funktioniert nur CID Schriftarten verwenden und Schrift als Kurven darstellen. Alle anderen Optionen werden ohne die ęąśżćł Sonderzeichen ausgegeben easzcl.
Im Bericht verwenden wir standardmäßig Arial. Was sollte ich also als Defaultwert verwenden. Wäre hier als Kurven darstellen eine Option? Oder könnte es zu Problemen führen?
Grüße
Thomas