für meine Layouts möchte ich eine CSV-Datei als Datenquelle verwenden mit ~ 1100 Spalten. Der Web Report Designer benötigt zum Aufklappen der Gruppe mit den Feldern ~ 10sek und das Zusammenklappen hängt nach ~20sek den Browser auf. Gibt es von Seiten des Web Report Designers ein Limit für eine maximale Anzahl an Feldern in einer Gruppe?
wir werden uns das mal ansehen. Über 1000 Felder sind natürlich - auch aus Usability-Sicht - ein Wort. Allerdings sollte der Browser nicht einknicken, schon gar nicht beim Schließen von Nodes. Wir schauen mal, was wir da an Möglichkeiten haben, ich werde mich hier wieder melden.
danke schonmal für die Antwort. Bin gespannt, was ihr findet
Wie wäre denn alternativ aus eurer Sicht der beste Weg, um eine sehr große Menge an Daten (normalisiert in mehreren Tabellen) bereitzustellen? Alles im Memory führt ggf. dazu, dass dieser knapp wird bei mehreren gleichzeitigen Prozessen.
Wenn es mehrere Tabellen sind ist es eigentlich besser, entweder direkt auf die Tabellen zuzugreifen (z. B. mit einem der SQL-basierten Provider oder gleich dem DbCommandSetDataProvider). Da haben wir eine große Auswahl. Hintergrund: wenn die Daten auf Tabellen aufgeteilt sind müssen ja beim Aufklappen “nur” die Felder je Tabelle angezeigt werden, das dürften in der Regel deutlich weniger als in der CSV sein. Hierfür haben wir diverse Optimierungen (s. Geschwindigkeitszuwachs beim Designer für große Datenbanken | Blog).
Wir konnten das Problem hier im Übrigen leider nicht nachstellen - wohl eine Verzögerung von ca. 10 Sekunden beim Öffnen der Node, aber kein “Hängen” im Browser. Wir haben das auch analysiert, das Problem scheint in der von uns verwendeten Treeview-Komponente zu liegen (rc-tree - npm). Ich nehme an, dass die nicht für so viele Einträge optimiert wurde. Da sind uns vermutlich die Hände gebunden. Insofern würde sich die o. g. Aufteilung tatsächlich anbieten.
10 Sekunden ist ja quasi hängen Aber ich verstehe das Problem mit dem Tree. In einem anderen Fall haben wir ein ähnliches Problem.
Die einzelnen Tabellen kann ich leider nicht so ohne weiteres direkt übergeben, da einige Operationen im Client an den Daten passieren müssen, bevor diese an L&L übergeben werden können.
Wenn wir die Daten manuell in separate Tabellen (z.B. DataTables) aufteilen, gibt es eine Möglichkeit ohne Verwendung des InMemoryDataProvider die Relationen zwischen den Tabellen zu behalten? Problem ist sonst der höhe Speicherverbrauch bei sehr vielen Daten, die zum Zweck der Relationen alle geladen werden müssen.
Gibt es eine Möglichkeit ohne Verwendung des InMemoryDataProvider die Relationen zwischen den Tabellen zu behalten?
Klar, ihr könntet z. B. ein DataSet mit Relationen verwenden. Oder alternativ auch einen eigenen Datenprovider schreiben, der könnte auch die clientseitigen Operationen vornehmen. Je nachdem, was das für Operationen sind könnte sich auch ein SQL-Provider anbieten, bei dem ihr den AutoDefineField-Event handled, da kommt jedes Feld vorbei und kann z. B. unterdrückt oder inhaltlich geändert werden. Zudem könnt ihr im AutoDefineNewLine-Event zusätzliche Daten anmelden, die nicht so in der Datenquelle vorhanden sind. Da gibt es viele Möglichkeiten. Ist da vielleicht schon was für euch dabei?
Das mit den DataSets ist klar. Das würde aber alles bedeuten, die Daten alle im Speicher zu haben oder meinst Du etwas anderes? Die Idee mit dem CSV oder mehreren CSVs für die Tabellen war, das wir nicht alles im Speicher haben, da dies mehrere Gigabytes sein können.
Damit die einzelnen Tabellen zusammenhängend über Fremdschlüssel Relationen haben, müssen diese auch an L&L übermittelt werden oder kann man diese Relationen auch im Designer noch herstellen. Bspw. haben alle Tabellen eine ID über diese alle verknüpft sind.
Solange es einfache Relationen sind (also Primär-/Fremdschlüssel, die gleich sein müssen) sollte es bei DataTables performant sein, wenn ihr die Relationen per Filter im Designer nachbildet (vgl. Mit List & Label Elemente über Filterbedingungen verknüpfen | Blog). Wichtig ist, dass der Filter auf der Datenbank und nicht im Designer ausgeführt wird, das erkennst du im Formelassistenten an diesem Hint hier:
Allerdings verstehe ich den Ansatz mit den DataTables dann nicht - auch die sind ja im Speicher. Wenn ihr das komplett umgehen wollt führt für mich kein Weg am direkten Datenbankzugriff oder einem eigenen Provider vorbei, dann werden die Daten immer erst on demand in dem Moment geladen, wenn sie auch gebraucht werden.
Genau, die DataTables sind im Speicher. Daher würde ich das ungerne so machen wollen. Vielleicht habe ich mich ungenau ausgedrückt. Diese kamen nur daher ins Spiel, damit wir darüber die Relationen, die wir in den CSVs verloren haben wieder herstellen konnten. Das bringt ja nur nichts, weil dann brauch ich auch nicht erst ein CSV schreiben, wenn nachher wieder alles im Speicher ist .
Wenn ich das jetzt alles richtig zusammenfasse, haben wir zwei Möglichkeiten:
Eine große CSV mit vielen Spalten (Browser reagiert für eine gewisse Zeit nicht)
Viele Tabellen in Memory verknüpft mit Relationen (Potenzielles Problem mit Speicherverbrauch)
Die Idee mit der CSV war, die Daten zeilenweise per stream in die Datei zu schreiben, um so den Speicherverbrauch sehr gering zu halten. Die CSV sollte dann als komplette Datenquelle funktionieren.
Ich werde mir nochmal den Blogeintrag bzgl. der Verknüpfung über Filter ansehen. Eventuell hilft uns auch der Ansatz mit einem eigenen Provider.
bzgl. einzelner Tabellen als Datenquellen habe ich nochmal Rückfragen.
Unsere aktuellen Layouts sind so aufgebaut, dass die Relationen bereits in den Tabellen der Datenquelle abgebildet sind. Mit dieser Struktur können wir u.a. auch die Funktion Tabelle in Tabelle abbilden.
Für einzelnen Tabellen (mit oder ohne Relationen) als Datenquelle im Web Report Designer stellen sich daher jetzt noch Fragen:
Kann mit einzelnen Tabellen als Datenquellen die Funktion Tabelle in Tabelle verwendet werden?
Können einzelne Felder aus unterschiedlichen Datenquellen in den Layouts verwendet werden, die über Filter verknüpft werden?
Wir bräuchten z.B. für eine Tabellenzeile Werte aus bis zu vier Tabellen der Datenquelle.
Bisher war dies alles möglich, da wir die Daten alle verknüpft hatten. Auf Grund von einer anderen Datenbereitstellung und Anforderungen muss dies allerdings geändert werden.
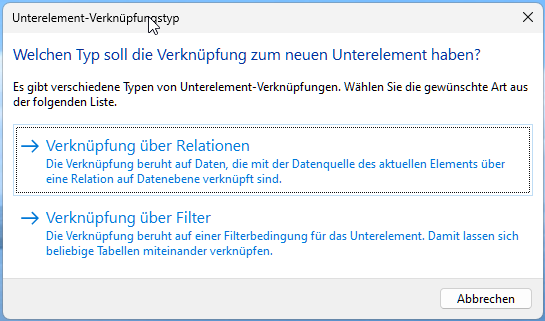
Solange die Zieltabelle die Filterung wie oben von mir beschrieben unterstützt sollte das kein Problem sein. Auch beim Einfügen einer Tabelle-in-Tabelle bekommst du die Auswahl hier:
und kannst dann auch ohne “echte” Relation die Daten verknüpfen. Das ist für den Endanwender allerdings nicht ganz so intuitiv, da er wissen muss, wie die Verknüpfungen in der Datenbank gedacht sind. Aber vielleicht gibt es bei euch ja keine Endanwender im Designer ? Das scheint mir auf jeden Fall - wenn es keinen eigenen Provider oder direkten Datenbankzugriff geben soll - ein gangbarer Weg.
Endanwender im Designer kann es geben. Aber das ist nicht die Regel. Aber das ist natürlich ein berechtigter Hinweis.
Wie wäre denn in dem von mir beschriebenen Fall der best Practice von euch als Entwickler von L&L? Wie sollte man bei einem großen Export mit vielen Tabellen und Relationen aus eurer Sicht vorgehen, wenn ein direkter Datenbankzugriff nicht möglich ist und auch der Arbeitsspeicherverbrauch relevant ist?
Ich möchte gerne vermeiden, dass wir einen Weg gehen, der von euch für diesen Fall eigentlich nicht vorgesehen ist
Der Königsweg wäre für mich ein eigener Datenprovider. Der könnte z. B. intern ein DataSet für die Datenhaltung verwalten, das aber erst dann füllen, wenn eine Tabelle auch wirklich benötigt wird. So wären dann zwar Daten im Speicher, aber immer nur die, die gerade gebraucht werden.
Alternativ könntet ihr natürlich auch mit einer zweiten Datenbank arbeiten, die eure angereicherten Tabellen enthält und rechtetechnisch auf ein reines Lesen eingeschränkt ist. Dann könntet ihr euch daran binden. Je nachdem, wie das Szenario bei euch aussieht könnte das ja auch eine temporäre Datenbank sein, die nach Abschluss der Session wieder gelöscht wird.
Die Filterrelationen sind aber für uns genauso fein, nur muss man da halt immer dran denken, den Datenfilter wie gewünscht einzustellen. Und für Endanwender ist das Thema eher schwierig, wenn die Relationen von Beginn an da sind kann man nicht so viel falsch machen .
Das wäre anstatt CSV. Der eigene Provider ist eine komplette Datenquelle. In z. B. der GetTable-Methode des Interface würdest du einen DataTable mit den benötigten Daten füllen und dann als Table-Interface wrappen. Das Thema ist ein wenig komplexer, das braucht ein bisschen Einarbeitung. Wenn ihr das machen wollt würde ich einen Blick in unsere Datenprovider empfehlen, ihr habt ja Sourcecode-Zugriff. Besonders der ADO-Provider wäre dann interessant.