Wozu ist bei Diagrammen (oder auch bei Tabellen) die Angabe der Datenquelle gut, wenn den Datenreihen oder Spalten ohnehin einzelne Felder zugeordnet werden, d.h. die Verknüpfung mit den Daten hier sowieso vorhanden ist?
Mein Problem ist, dass ich die in einem Diagramm dargestellten Datenreihen indirekt angeben will/muss, d.h. die anzuzeigenden Felder sollen durch Angabe eines Strings, der einen Feldnamen enthält, definiert werden. Dies funktioniert allerdings nur, wenn dieser Feldname innerhalb der Datenquelle des Diagramms ist, was jedoch bei der Erstellung des Templates nicht feststeht bzw. sich dynamisch ändern kann. Könnte die Datenquelle auch per GetValue(“tableName”) angegeben werden (also auch indirekt), so würde das wohl funktionieren.
Falls man aber in einem Diagramm Datenreihen aus verschiedenen Datenquellen/Tabellen zusammenführen will, wird dies dennoch nicht gehen. Warum ist diese Datenquellen-Angabe also nötig? Welche Möglichkeiten hätte ich, um Felder, deren Namen in anderen Variablen als Text vorliegen, durch indirekte Angabe in einem Diagramm darzustellen?
ppreuschoff
(combit Support - Patrick Preuschoff)
2
Könnten Sie uns die Zielsetzung und den Aufbau der Datenquelle kurz umschreiben, sodass wir einen besseren Einblick in Ihre Fragestellen bekommen.? Gerne auch per Screenshot(s)
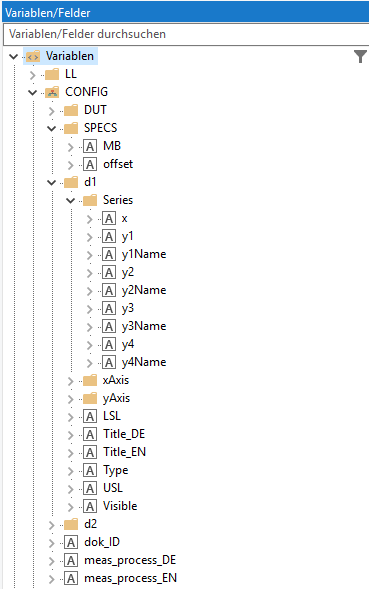
Meine Datenquelle(n) sind hierarchisch strukturierte Messprotokoll-Dateien (TXT), die über einen Parser in L+L eingelesen werden. Dabei ergeben sich verästelte Strukturen, deren Knoten und Variablen/Felder aber nicht immer gleich sind, d.h. je nach Produkt mal da sind, nicht da sind oder anders heißen. Die Datenbasis ist also relativ heterogen. Beispiel:
Um die Anzahl der L+L-Templates gering (oder noch besser bei 1) zu halten und somit Layout von Inhalt zu trennen, gibt es derzeit die Möglichkeit, zusätzliche config-Variablen zu verwenden, die aus einer Textdatei gleichen Formats zusammen mit der eigentlichen Datenbasis eingelesen werden. Beispiel:
Durch diese produktspezifischen config-Parameter kann nun eine Verknüpfung von produktspezifischer Datenbasis und dem darzustellenden Inhalt vorgenommen werden … so zumindest die Idee.
Im Beipiel steht in CONFIG.d1.Series.x der Variablenname des Feldes aus der Datenquelle, das im ersten Diagramm (d1) auf der x-Achse dargestellt werden soll.
Im Falle von Tabellen ist es möglich, mit der config-Datei eine Feldvariable (z.B. CONFIG.DUT.description) zu erzeugen, deren Einträge die Namen anderer Variablennamen (solche aus der eigentlichen Datenquelle) als Text enthalten. Die zugehörige Spaltendefinition GetValue(CONFIG.DUT.description) liefert das gewünschte Ergebnis, also eine Tabellenspalte variabler Länge in Abhängigkeit der Länge von CONFIG.DUT.description.
Bei Diagrammen würde ich mir nun einen ähnlichen Mechanismus wünschen. Beispiel:
Der Koordinatenwert der x-Achse ist als Evaluate(Getvalue("CONFIG.d1.Series.x")) definiert, wobei CONFIG.d1.Series.x den Feldbezeichner measurement_values.measurement_table_1.motor_pos (als Text) enthält, eben weil dieses Feld auf der x-Achse angetragen werden soll.
Leider funktioniert dies nur, falls in der Datenquelle des Diagramms auch measurement_values.measurement_table_1 eingetragen ist. Andernfalls erscheinen keine Daten im Diagramm. Die Datenquelle des Diagramms kann man jedoch nicht indirekt/variabel definieren oder - um zu meiner Ausgangsfrage zurückzukommen - warum braucht man diese Datenquellenangabe überhaupt, wenn den Datenreihen ohnehin die entsprechenden Felder zugeordnet werden?
Im Falle von Tabellen ist di eSituation ähnlich. Auch hier wird eine Datenquelle angegeben, wobei es jedoch kein Problem gibt, wenn in der Tabelle letztlich indirekt auf Felder außerhalb der Datenquelle verwiesen wird.
Wenn das Ganze so volatil ist scheint mir die Herangehensweise über den Designer nicht optimal. Ich sehe zwei Möglichkeiten, das (im Ergebnis) etwas einfacher umzusetzen:
Sie könnten einen eigenen Datenprovider schreiben, der die Daten so abstrahiert, dass immer die richtigen Inhalte z.B. in einer Metatabelle “ChartValues” enthalten sind. Die Inhalte dieser Tabelle ergeben sich dann dynamisch aus den jeweiligen Vorgaben, innerhalb des Designers kann aber mit festen Werten statt Evaluate gearbeitet werden. Dies hat auch den Vorteil, dass Intellisense und Typenvergleiche zuverlässig funktionieren.
Sie könnten die Projektdateien auch komplett dynamisch mit dem Objektmodell erstellen. Dazu könnten Sie - wenn Sie mit .NET arbeiten - auch einmalig eine Vorlage interaktiv im Designer bauen und dann mit dem Code aus dem “C# Dynamic Generated List & Label DOM Code”-Beispiel den Code für die Erstellung des Projekts automatisch generieren und anschließend anpassen. In diesem Falle sparen Sie sich ebenfalls den Evaluate-Workaround und brauchen nur an wenigen Stellen (genau an denen, an denen Sie aktuell mit Evaluate arbeiten) den Code anpassen.
Um die Ursprungsfrage zu beantworten - der Tabellenname für das Chart ist notwendig, damit klar ist, über welche Daten überhaupt iteriert werden soll. Charts sammeln sich ja ihre eigenen Daten und aggregieren diese. Dafür wird die Datenquelle durchlaufen. Ohne Datenquelle gibt es nichts, was LL durchlaufen könnte…
Die Idee gefällt mir gut. Leider bin ich Endanwender, d.h. ich muss mich da mit dem Ersteller der Parseranwendung auseinandersetzen … Mal sehn …
Ist für mich nicht praktikabel, weil ich an der Stelle nicht eingreifen kann (s.o.) und außerdem keine Ahnung von .NET habe.
Nunja. Da muss man wohl mehr über die interne Funktionsweise von L+L wissen. “In meiner Welt” müsste es doch reichen, die Variablen oder Felder dort anzugeben, wo sie gebraucht werden, nämlich z.B. in den Reihendefinitionen. Warum man dazu noch zusätzlich ein übergeordnetes Objekt (die Tabelle) angeben muss … zumal dieses ja auch die Auswahl der Felder eingrenzt, erschließt sich mir hierbei immer noch nicht. Zudem funktioniert der gewünschte Mechanismus bei Tabellen … warum auch immer.
Nehmen wir einen ganz einfachen Fall - eine Tabelle mit Ländern und Umsätzen:
Land
Umsatz
Deutschland
1000
Frankreich
2000
UK
1500
…
…
Wenn ich hierüber ein Chart haben will müssen ja alle Länder mit ihren Umsatzzahlen übergeben werden. Daher muss diese Tabelle iteriert werden. Das erreiche ich leicht, wenn ich sie dem Chart als Datenquelle zuweise . Und wenn die Struktur komplexer wäre und ich unterhalb der Tabelle noch weitere Daten hätte ist es ja wichtig festzulegen, dass diese Unterdaten auch iteriert werden sollen weil sie für das Ergebnis eine Rolle spielen.
Vielleicht fragen Sie tatsächlich mal bei Ihrem Hersteller an - so sehr ich auch den Hut davor ziehe, wie tief Sie in die Designer-Funktionalitäten eingestiegen sind so unwohl ist mir dabei, wenn ich das Gefühl habe, dass das eigentlich von der Applikation unterstützt werden könnte und es dann vergleichsweise einfach zu designen wäre. Ob ihr Hersteller das auch so sieht ist natürlich nicht klar - je nach Programmiersprache und Umgebung kann das auch ein beträchtlicher Aufwand sein.