Ich habe ein Python Script das PDFs auf bestimmte Werte untersucht. Das klappt auch wunderbar, aber nicht mit PDFs die ich mit List&Label erstellt habe. Wer hat eine Idee?
Ich nehme an, dass mit “Werte” Inhalte im PDF gemeint sind? Dann vermute ich das Problem hier eher auf der Seite des Verarbeitens.
Welche Python-Bibliothek wird denn für das Auslesen der PDFs verwendet? Die PDFs sind ggf. komprimiert, eventuell auch verschlüsselt, verwenden je nach Font unterschiedliche Darstellungsformen etc. pp. Wenn die Bibliothek damit nicht umgehen kann können auch keine Werte ausgelesen werden.
Hallo Herr Bartlau,
ich vewende PyPDF2. Wenn ich ihre Programmier-Referenz durchsuche, finde ich alle Werte die ich suche.
Ich benutze “LlStgsysStorageConvertA” um aus .ll .pdf zu machen.
Ich habe jetzt einmal ein PDF mit den Standardsettings erzeugt (brief.brf aus der Beispielanwendung, das File hängt an):
export.pdf (35.1 KB)
Wenn ich dann folgendes mache
import PyPDF2
def extract_text(pdf_file_path):
with open(pdf_file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
page = reader.pages[0]
text = page.extract_text()
return text
pdf_file_path = 'export.pdf'
text = extract_text(pdf_file_path)
print("Text:")
print(text)
erhalte ich
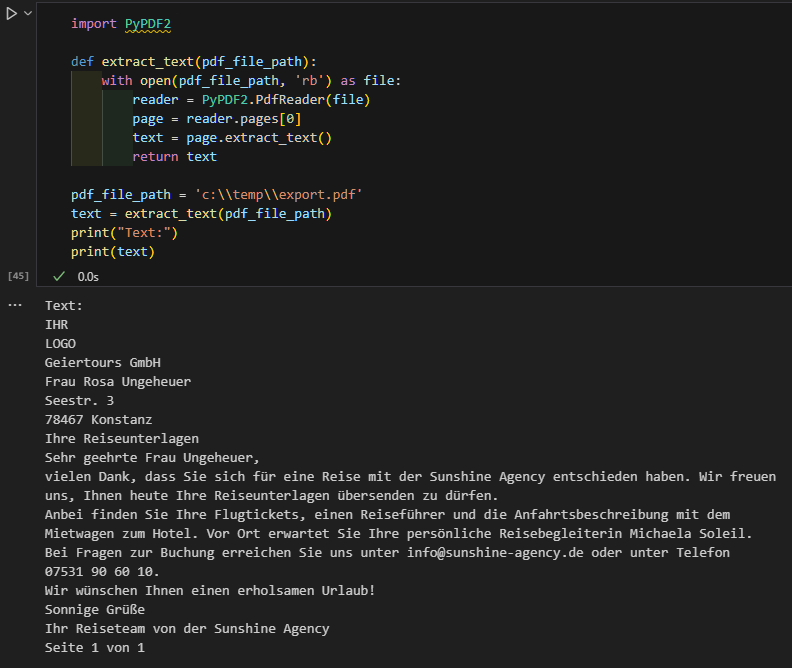
Damit könnte man dann arbeiten. Können Sie sehen, was bei Ihnen anders läuft ![]() ?
?
Hier meine pi.file.
mport os
import PyPDF2
import argparse
def search_pdf_files(folder_path, search_term):
results = {}
#----------------------------------------------------------------------------------
# Aufruf py pdfparser2.py lw:\PDFOrdner Suchwert lw:\AusgabeOrdner\ausgabedatei.txt
#----------------------------------------------------------------------------------
# Durchsuche den angegebenen Ordner nach PDF-Dateien
for filename in os.listdir(folder_path):
if filename.endswith(".pdf"):
pdf_path = os.path.join(folder_path, filename)
with open(pdf_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
num_pages = len(reader.pages)
occurrences = 0
# Durchsuche jede Seite nach dem Suchbegriff
for page_num in range(num_pages):
page = reader.pages[page_num]
text = page.extract_text()
occurrences += text.lower().count(search_term.lower())
# Speichere die Anzahl der Vorkommnisse für diese PDF-Datei
if occurrences > 0:
results[filename] = occurrences
return results
def write_results_to_file(results, output_file, search_term):
with open(output_file, "w") as file:
file.write(f"Suchbegriff: {search_term}\n")
file.write("Anzahl der Vorkommnisse jedes Suchbegriffs\n")
file.write("=====================================\n")
total_occurrences = 0
for filename, occurrences in results.items():
total_occurrences += occurrences
file.write(f"Der Begriff '{search_term}' wurde insgesamt {occurrences} Mal in '{filename}' gefunden.\n")
file.write("Ende der Liste\n")
file.write(f"Gesamtzahl der Vorkommnisse: {total_occurrences}")
if __name__ == "__main__":
# Parse der Argumente
parser = argparse.ArgumentParser(description="Suche nach einem Begriff in PDF-Dateien.")
parser.add_argument("folder", help="Pfad zum Ordner, der durchsucht werden soll")
parser.add_argument("search_term", help="Der Suchbegriff, der gefunden werden soll")
parser.add_argument("output_file", help="Pfad zur Ausgabedatei")
args = parser.parse_args()
folder_path = args.folder
search_term = args.search_term
output_file = args.output_file
# Suche nach dem Suchbegriff in den PDF-Dateien im angegebenen Ordner
results = search_pdf_files(folder_path, search_term)
# Schreibe die Ergebnisse in die Ausgabedatei
write_results_to_file(results, output_file, search_term)
print("Die Suche wurde abgeschlossen. Die Ergebnisse wurden in die Ausgabedatei geschrieben.")
Ich habe das Skript auf einen Folder losgelassen, in dem mein PDF aus dem Thread hier weiter oben lag. Das Ergebnis:
Suchbegriff: Geiertours
Anzahl der Vorkommnisse jedes Suchbegriffs
=====================================
Der Begriff 'Geiertours' wurde insgesamt 1 Mal in 'export.pdf' gefunden.
Ende der Liste
Gesamtzahl der Vorkommnisse: 1
Insofern sehe ich nicht, was das Problem ist? Vielleicht ein anders erzeugtes PDF?
Das Problem ist, das meine mit L&L erstellten PDFs mit dem Script nicht funktionieren!
Alles zurück, ich habe den Fehler. Der Script ist OK.
Wo lag das Problem ![]() ?
?
Das Problem ist das ich in allen PDFs Ergebnisse bekomme, nur nicht in denen die ich selbst mit L&L erstelle. Es liegt wahrscheinlich daran, das ich .ll in .pdf mit LlStgsysStorageConvert konvertiere.
Wenn ich mit LlStgsysStorageConvert in XLS kenvertieren will, welche Optionen muss ich setzen, damit das funktioniert. Meine Programme sind in Cobol erstellt.
Häng doch hier mal ein solches PDF an.